ComfyUI.Tokyo
複数条件の場合はキーワードの間にスペースを入れてください。例 ksampler controlnet
SD15_Florence2Run_New-Subgraph 画風の変換
ComfyUIでFlorence2(Microsoftが開発した多機能な視覚基盤モデル)を活用し、より高度なプロンプト制御やマスキングを行うためのワークフロー設定です。
1. Florence2Run Node
Florence2は「画像を見て説明する(Caption)」だけでなく、特定の指示(Task)をこなす非常に強力なノードです。
- num_beams を 1 に設定する理l由:
推論の探索幅を絞ることで、生成速度を上げ、出力されるテキストをよりシンプル(決定論的)にします。 - String Function との組み合わせ:
Florence2が画像から生成した「説明文(Caption)」と、クリエイターが入力した「追加プロンプト(Creator Prompt)」を結合させます。これにより、「元の画像の特徴を維持しつつ、新しい要素を加える」という高度なプロンプト作成が可能になります。
2. Show Text Node
ComfyUI標準では文字列の中身を直接画面上で確認することが難しいため、このノードは必須の「デバッグツール」となります。
- 役割: Florence2が画像からどのような説明文を抽出したのか、あるいはString Functionで合成された最終的なプロンプトがどうなっているのかを、ワークフロー上でリアルタイムにテキスト表示します。
- 利点: 生成に失敗した際、原因が「画像認識(Florence2)」にあるのか「生成設定」にあるのかを即座に判断できます。
3. New Subgraph Node (カスタム構成)
これは複数のノードを1つにまとめた「グループ化」されたコンポーネントを指しています。
- 内部構造:
CLIP Text Encode(プロンプトをAIが理解できる数値に変換するノード)と String Function(文字列操作)が合体しています。 - メリット:
ワークフローの見栄えがスッキリするだけでなく、Florence2から出力されたテキストをそのままCLIPに渡し、スムーズに画像生成プロセスへ移行できる「パイプライン」として機能します。
4. 各生成WorkflowにおけるFlorence2Runの活用
SD1.5やSDXLなどのワークフローにおいて、Florence2は「目」の役割を果たします。
■ IP-Adapterとの違い
- IP-Adapter: 画像の「特徴・雰囲気」を数学的に抽出し、似たような画風(Style)を転送します。
- Florence2: 画像を一度「言語(Text)」に変換します。これにより、IP-Adapterでは難しかった「画風だけをガラッと変える(例:写真をイラストにする)」といった指示が、テキスト経由で柔軟に行えるようになります。
■ 部位検出とMask出力
Florence2は「物体がどこにあるか」を座標(Bounding Box)や領域で出力できますが、次の特性があります。
| 機能 | Florence2 | Segment Anything 2/3 (SAM) |
| 得意なこと | 「青い服の男」など、言葉での指定 | 境界線の極めて精密な切り出し |
| 精度 | 矩形(四角形)や大まかな指定に強い | ピクセル単位で正確に分離する |
| 使い分け | プロンプト連動型の編集 | 精緻なコラージュや合成用マスク |
補足: SAM3(最新のSegment Anything Model)は、重なり合った物体や複雑な輪郭を捉える能力において、現時点でFlorence2を大きく上回る精度を持っています。
Workflow
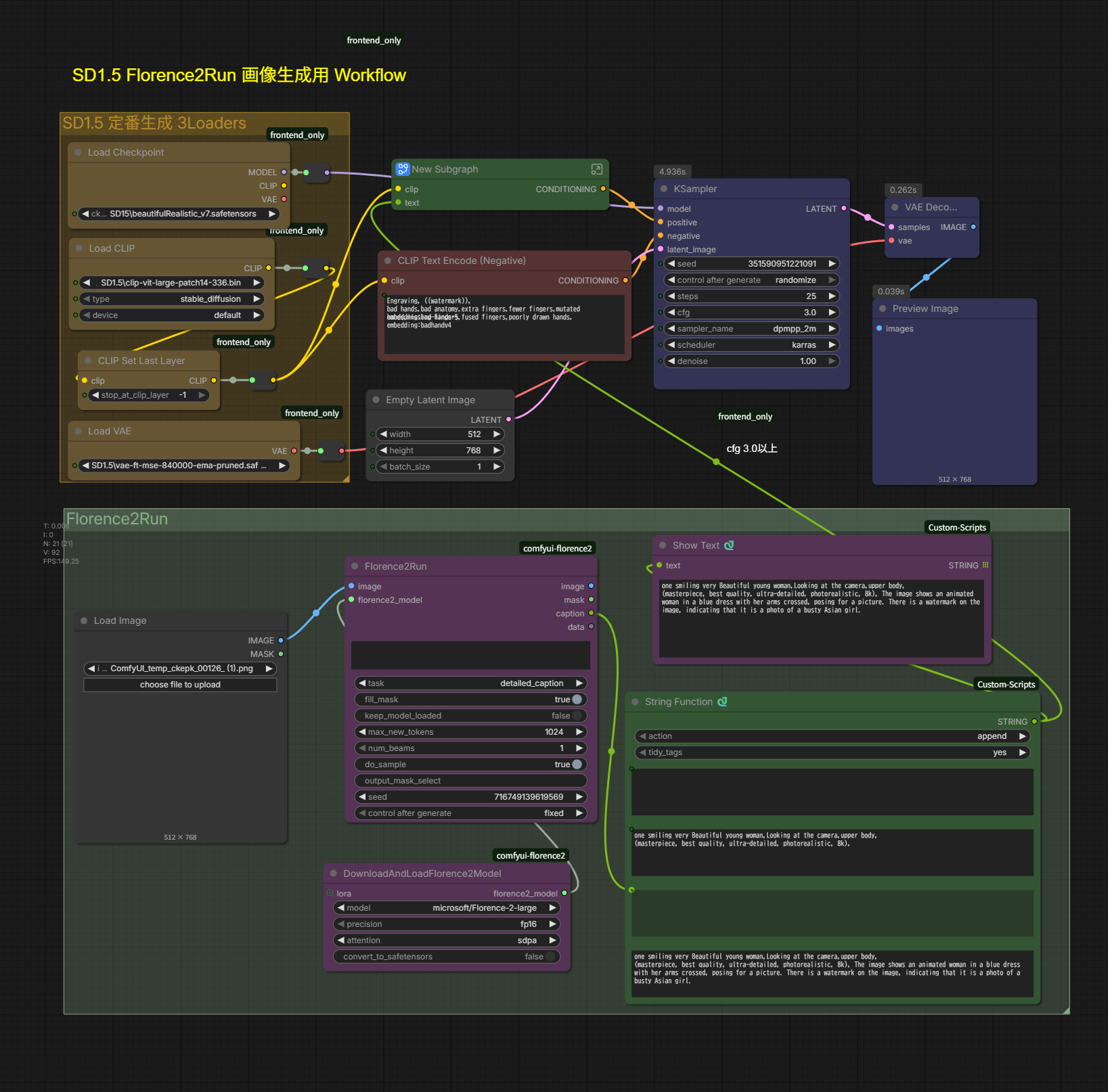
+prompt
- one smiling very Beautiful young woman,Looking at the camera,upper body, (masterpiece, best quality, ultra-detailed, photorealistic, 8k),
-prompt
- Engraving, ((watermark)), bad hands,bad anatomy,extra fingers,fewer fingers,mutated hands,missing fingers,fused fingers,poorly drawn hands, embedding:bad-hands-5 embedding:badhandv4

in(512 x 768)

out(512 x 768)

Florence2Runについての勉強でした。